『愛善健康法』のKindle本化1 a kindle book of “Aizen-kenkoho” part 1
はじめに
この『愛善健康法』のKindle本への道は,OCRに期待して でも解説している。木庭眞さんから,デジタル化のサポートが頂けるようなので,下準備を行っている。父の著作は,ある時期,東京都南分所に属しておられる鈴木智子さんの邦文タイプによるサポートで実現していた,と推定している。その成果はタニハに現在も残っている。
ぼくが小学四年生の頃か,こどもの日にどこかに連れて行けと駄々をこねて,自宅から10分ほどの父の仕事場があった「みずほ会館」に連れられて行った。そこでおそらく,いさみ寿司から昼食として寿司でも取ってもらったように思う。不満であった。眞さんも一緒だったのではないか。父の机がある大きな部屋からは保津川の氾濫原を経て牛松山が正面に見える。この大部屋の手前には,外から光が入らない比較的小さな部屋があって,鈴木倶子さんが忙しく邦文タイプを打っておられた。入る時,優しい挨拶を頂いたように思うが。ノーベル賞の湯川秀樹の息子さんも父のサポートをされていた。何か質問に来られて,知らない方だったので父に聞いたら,そういう答であった。
その日は父の頭の白髪抜きをして過ごした。こんなに抜いて大丈夫かと聞いて問題ないというような回答があったことも思い出される。抜いた1/4ぐらいは黒かったのでは無いか。これも聖師の教えに基づくものなのか?
眞さんには鈴木智子さんの邦文タイプ結果の『霊界物語の大精神』のデジタル化をまずはお願いしようと思ったが,成果がすぐには出ず,やる気を無くされてもと思い,正規の印刷物で字数も少ない『愛善健康法』を先にと今日,考えた。眞さんにデジタル化の全過程を知って頂くべく,ここに手法を残すことにした。
追記 Oct. 8, 2022: 松田宏さんから鈴木倶子さんの写真などが届いた。鈴木倶子さんの消息がわからない。写真1と写真2はいずれも,みずほ会館で,1955年当時。写真2の倶子さんは,松田宏さんが東京から訪ねてこられたからか,すごく嬉しそう。上段左端は木庭次守(38歳),上段中央はのちの本部長櫻井重雄さんか。写真1の部屋は,鈴木倶子さんが邦文タイプを打っておられた部屋ではないかと思う。
松田さんから送られたコピー写真を,BrotherのA3対応複合機でスキャンしたが1200dpiでも,写真2では顔のテカりが大きかった。富士通のScansnapは簡易のスキャナー(最大600dpi)という印象であったが,自然なスキャン画像で大きな違いがあった。このことから考えると,次に続く「1 Adobe PhotoshopによるOCR前の準備」以下で述べたBrotherの複合機を使うよりも,このBrother複合機で紙コピーして(A4に縮小),Scansnapで一気にスキャンした方が,画質も効率もより優れたコンテンツを得られる可能性がある。


1 Adobe PhotoshopによるOCR前の準備
OCRに期待して で本のスキャン手法などについては記している。眞さんが複合機を持っていないのであれば,ぼくがこの章の作業は実施してゆくことになるだろう。このスキャンは300 (dpi)で実施していた。
スキャンファイル数は40点で,これをおよそ次のプロセスで切り取りと2階調化を実施した。
1 イメージ > 画像の回転 > 角度入力 > 時計回りか反時計回り。
2 範囲指定して,イメージ > 切り抜き。
3 見開きページ中央の綴じ代部分は,編集 > 消去。
4 切り取った全域を選んで,イメージ > 色調補正 > 2階調化 目分量だが,濃くすると見出しがつぶれるなどする。
5 ファイル > 別名で保存。ファイル名称をページ番号などに替えて,保存するフォルダを指定し,高画質(8)を選ぶ。
スキャンしたファイルのうち,表紙,内表紙は,基本的には表紙などを作成するのに使用する。
ocrに供するファイルを,Aizen-kenkoho_for_OCRというフォルダに入れた。この本は目次などにページ1〜8があり,その後,ページ1〜62が続くので,前者のページにはfを冠している。つまり前者のページはpf1.jpgなどとし,後者のページ48と49の見開きファイル名は,p48_49.jpgなどとなっている。
2 OCR作業対象のファイル群をGoogle Driveにコピー
0 Google Driveを開く。
1 すでに愛善健康法のフォルダがあり,その中にスキャンファイルが入っていたので全部削除した。
2 My Driveを右クリックして,Folder uploadを選んで,macのファインダで,Aizen-kenkoho_for_OCRというフォルダを選ぶ。右下にアップロード過程が見え,完了すると,✅️が表示される。
3 My Driveに戻って,愛善健康法のフォルダに,Aizen-kenkoho_for_OCRというフォルダをドラッグアンドドロップする。この中のファイルの配列はmacのファインダ内のものと一致している。
3 OCR作業
全36ファイルのOCR作業をして,Word文書で出力して,全部ダウンロードすることになる。このOCR作業は,OCRに期待して に記述している。
上記投稿に示しているが,次のようにする。
1 各ファイルを右クリックして,Open with > Google Docs。
2 File > Down load > Microsoft Word (docx),とすると,Word形式でダウンロードできる。
3 Down loadフォルダ内のファイル群を新たにOCR_Wordというフォルダを作って,My Driveにアップロードする。
4 そして,そのフォルダを,愛善健康法フォルダに移動する。
4 OCR結果の共有
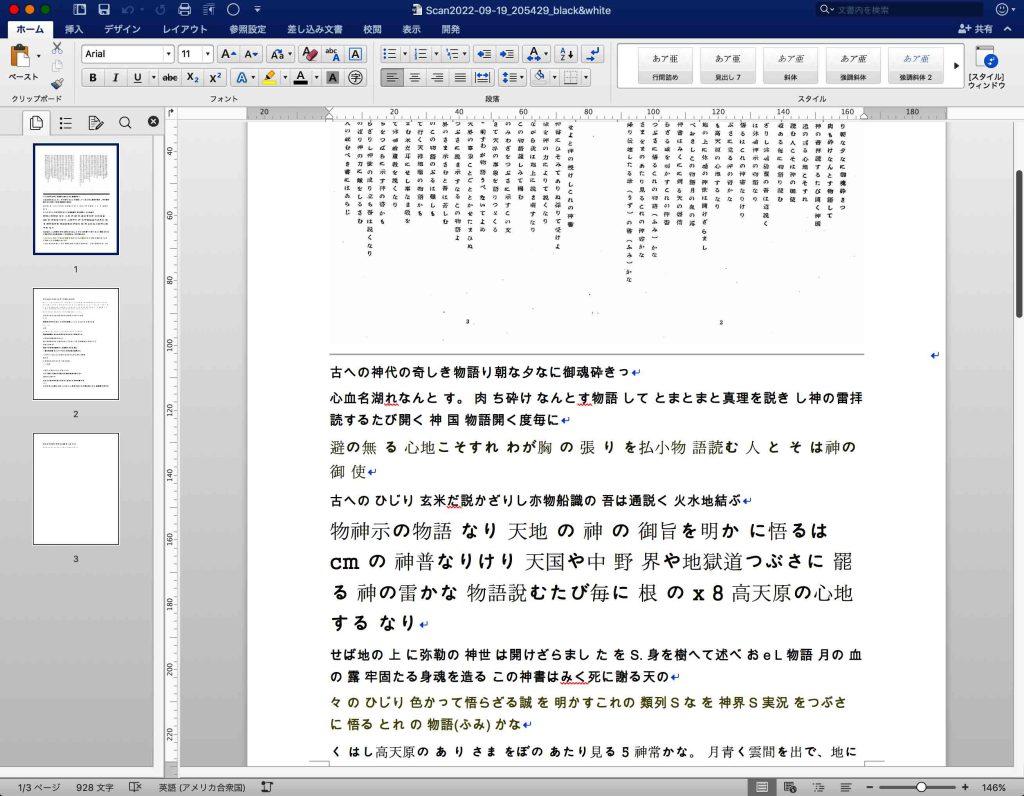
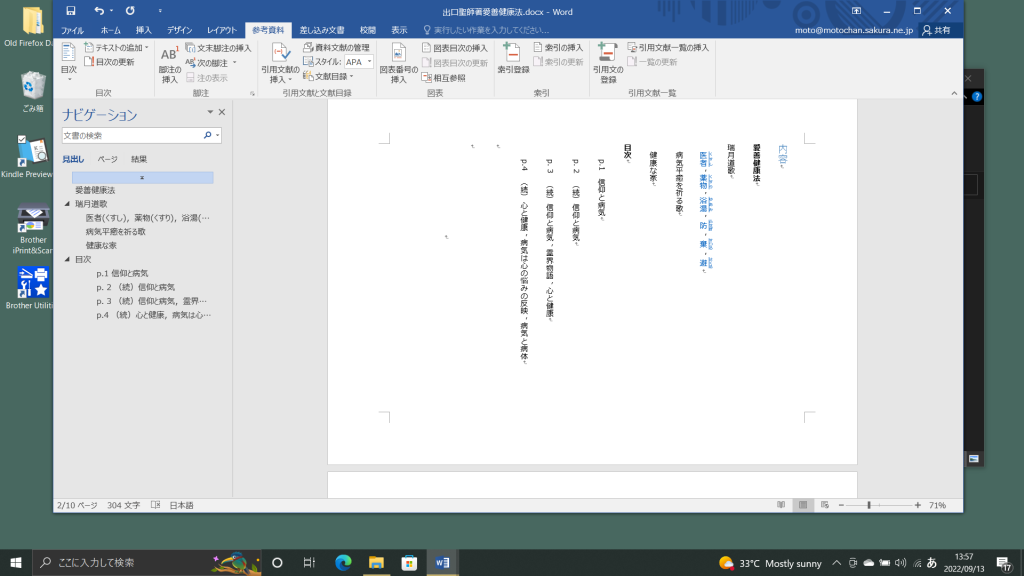
OCRの結果の一例を図1と2に示す。本文の例が図1である。ルビは最初に抽出されている。本文の解読力はほぼ100%近い。図2は目次部分である。⋯⋯⋯⋯⋯で,かなりの混乱がある。OCR結果を無視して,自らテキスト入力した方が良いのは明らかである。Kindle本ではページの概念は無い。目次それぞれにリンクを設定するのが良いだろう。本文の各項目をレベル2かレベル3にして,目次部分ではリンクを設定するのがベストだ。この作業はぼくがしますので,一行毎に,1項目名を入力してください。本文の項目名も一行をとって,ハードリターンで,その説明の段落を作成してください。

Google Driveで,愛善健康法のフォルダ(これからは,\愛善健康法とします)を右クリックし,☃+ Shareを選んで,木庭眞さんのメールアドレスを入れた。Googleメールアドレス以外でも受け付けるということであった。
革命的と言って良いほど,OCRの結果は良かった。ただ,目次などで縦の⋯⋯⋯⋯⋯などがページ番号に繋がる形の場合,かなり混乱がある。目次は別途,作成するので,目次に掲載された名称のリストだけ,整理して欲しい。
OCRの作業過程の結果として,文字に色が付いたり,サイズの大小が生じているが,フォントをメイリオにして,全部普通体regular styleにして欲しい。
5 Microsoft Word 縦書きキンドル書式
この書式については,別途掲載している。また,お伝えしたい。OCR結果のWordで作業はしないで,キンドル版の縦書き書式で,文書を元の本のスキャン表示に従って,整えてください。ルビも併せて追加して下さい。
おわりに
作業での連絡を通じて,この投稿をよりわかりやすいものにしたいと思っている。タニハではWi-Fi環境が無いのでパソコンでのネット作業はiPhoneを使ってtetheringすることになる。眞さんがこの環境を使っていない可能性がたかく,Google Driveの使い方などを眞さんに知って貰いたくて,亀岡市の公共Wi-Fi環境を調べた。亀岡市のガレリアだっけか,あるかなと思ったけど,どうも無いようだ。ネット検索すると,MacDonaldが3箇所にあった。ここだな。
以上,Sep. 27, 2022記。
追記 Oct. 8, 2022: 後日,MacDonaldに電話したら,Wi-Fiは提供していない,イオンはどうかって。で,イオン亀岡に電話したらオーケー。