
OCRに期待して using OCR Tool in Google Drive
はじめに
スキャン画像をほぼそのまま使ってキンドル本を出すという考えで試行錯誤したがうまく行かなかった。画像利用可能なオリジナル資料からKindle本 がその内容である。OCRをネット検索した結果からすると,Google Driveに付属している機能が優れているようである。読み取り言語として,日本語にも対応している。ぼくはGoogle Driveの有料版100GBコースに入っており,このWebサイトのバックアップだけに利用してきた。現在20GBぐらいで,かなりの余裕があり,これを使わない手は無いだろう。
1 Google DriveでOCRツールを使う方法
使い方: 東京経済大学TKUメール > OCRの利用
Google Drive Help:PDF や写真のファイルをテキストに変換する
2 実際にやってみる
1 画像の回転はプレビュー.appで
先の画像利用可能なオリジナル資料からKindle本 で取り扱った「愛善健康法」のスキャンファイルは 70 p.のものでブラザーのプリンターでスキャンしたファイル数は38個になる。これをPreviewすると,プリンターでのスキャン設定の問題ではあるが,すべて正位置と反時計回りで90度回転している。一気に回転する機能はAdobe Photoshopには無いので,macの写真.appを使ってみよう。極めて簡単,瞬時に終了。
で,元のフォルダが14.1MBが48.1MBと3.4倍に増大するが,個々のファイルは1.5MB以下なのでGoogle Drive Helpで示されている最大容量2MBよりは小さく問題はない。ただ,このスキャン対象の本は見開きで幅200mm x 高さ170mmほどで,かなり小さい。このpostingで試したい父の邦文タイプで作成された「簡易」印刷の書籍のサイズは見開きで,幅360mm x 高さ250mm程度であり,この写真.appを使うと1ファイルサイズは2MBを超えてしまう。写真.appは使えない。
さて,プレビュー.appを試してみた。全ファイルを入れたフォルダは13.6MBで何故か14.1MBよりも小さくなった。最大ファイルは417kBで,変化なし。Adobe Photoshopで種々の画像処理をしてもいいが,時間の無駄の可能性があるので,このまま,Google Driveに取り込もうと思う。
2 Google Driveへ
⒜ ChromeまたはGoogleで,Driveを開く。
⒝ My Driveを右クリックするとメニューが現れる。File uploadを選ぶと,ファインダ(またはエキスプローラー)でターゲットのファイルに行き着く。フォルダを選択することはできないが,フォルダ内に入って,全画像ファイルを一気に選択することができる。
⒞ 他のテーマのファイル群と区別するために,My Driveの表示のすぐ上方にある +Newを選んで現れるメニューからNew folerを選択して,この新しいフォルダに名前をつけて,先ほどアップロードした画像ファイル群を移動した方が良いだろう。新しいフォルダを先に用意する方がいいかもしれない。
⒠ 新しいフォルダに格納された個々の画像ファイルを一つ一つ選んでOCR化を実行してゆくことになる。個々のファイルを選んで右クリックするとメニューが現れる。Open with > Google Docsを実行する。その結果を次の図1に。
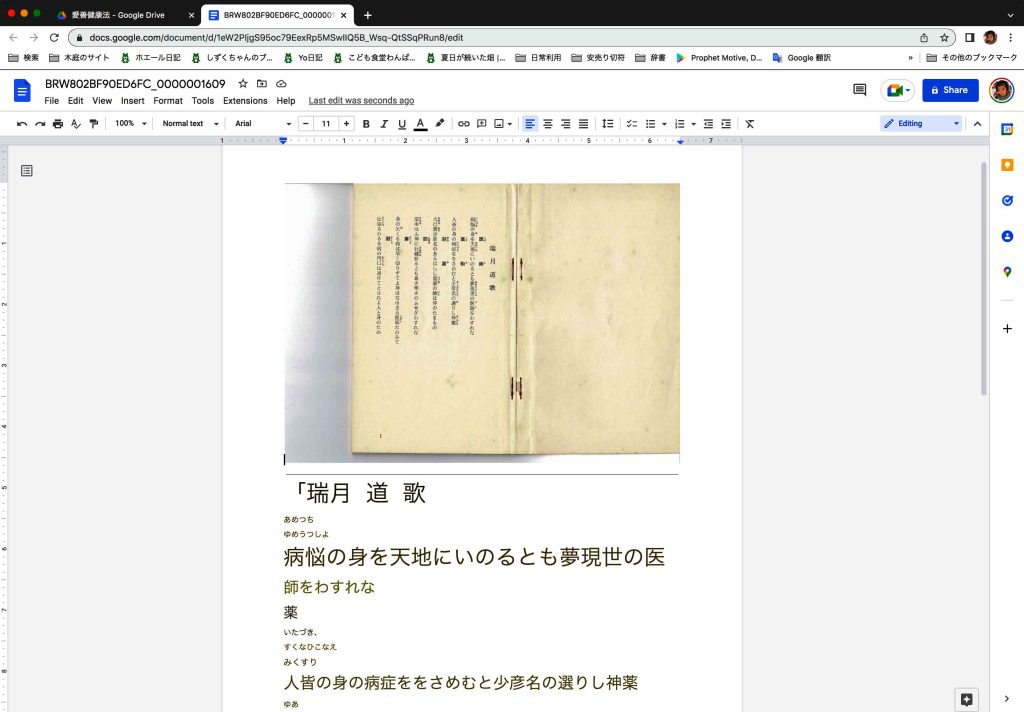
図1には読み取り結果の一部が見られるが,ほぼ脱落はない。ただ,瑞月道歌の次の最初のサブタイトル「医師(くすし)」が何故か脱落している。「病悩」のルビも脱落している。次のサブテーマの「薬物(くすり)」では,「物」が脱落している。などなど。原本を見ながら対照してゆけば問題はない。
⒡ 図2ではこのOCRを保存する過程を示している。図1にもMicrosoft Wordのようなメニューが上段に現れているが,このFile > Download > Microsoft Word (.docx)を選ぶと,一つ一つのOCR処理結果をWordファイルの形で保存できるので,すこぶる都合が良い。
図3ではこのダウンロードされたファイルを開いた様子である。全画像ファイルのOCR処理結果をこのように整理することができる。
⒢ Kindle本のMS Word原稿は縦書きであり,壊れたルビも復元する必要があるので,新たな縦書きに設定したWordファイルに,個々の出力結果を,「ペーストしてスタイルを合わせる」形で,まとめて行けば良いことになる。
『愛善健康法』のKindle本発行は,もう,楽々と,可能になった。ひたすらテキスト入力をしてゆくというboring situationは避けることができる。
3 邦文タイプの字の薄い本についてはどうだろうか
3.1 通常の解像度300 (dpi)で
画像利用可能なオリジナル資料からKindle本 の,3 Microsoft Wordで既存書籍スキャンデータからキンドル本出版の枠組み ⒝ 成功例(本来やるべき形だ),がスキャンの参考になる。ただ,ここで引用したpostingの場合のように画像そのものをファイルに取り込むことはしないので,2MB以内で出来るだけ解像度の高い画像を得る必要性がある。
macでスキャンして適切な環境条件を探す必要があるが,変更点は原稿サイズをB4としたことだけである。書籍は一般書と同じく,横に長く,その頭辺をプリンターの奥に押し込んで設置した。スキャン画像は上記と同様,プレビュー.appで時計回りに90度回転して保存した。その画像そのままは1.3MBで,これをAdobe Photoshopで2階調化(イメージ > 色調補正 > 2階調化)したものは256kBとなった。そして,上記のようにGoolge DriveでOCR処理をしてMS Wordとしてダウンロードした。
プリンターで印刷しようとしたが,当初,印刷設定を変更せずに印刷しようとしたらA4用紙を入れて通常使っているトレイでは印刷できず,トレイ変更を迫られた。Googleの設定では,USレター普通紙であった。そこで,ぼくが設定しているMicrosoft Word印刷(両面)に変更して初めて印刷することができたのである。
次の図4は画像そのままのOCRの実行結果の一部である。
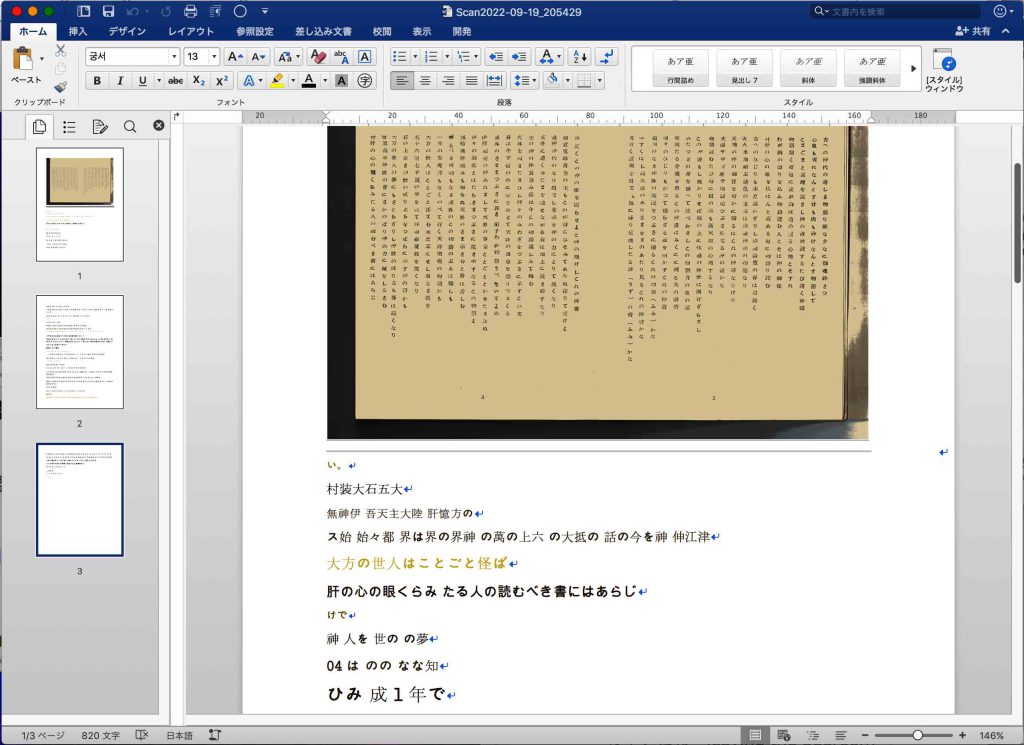
図5はAdobe Photoshopで二階調化したものである。目分量で閾値を決めている。
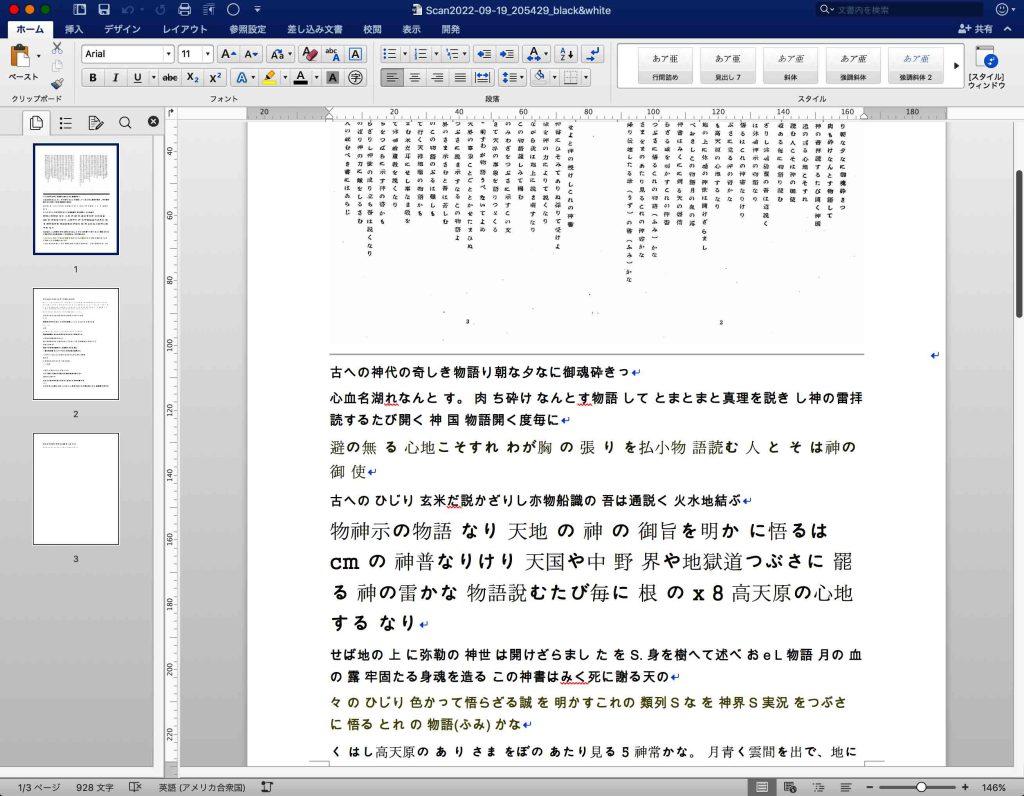
結論を先に言うと,二階調化したものが使用に耐えうると思う。OCRの結果は縦書きの配置に従っているのではなく,読み取られたものが,改行とは関係無く,続けられていることは注意しなければならない。
出版物の初めの5行を次に掲げる。なお,ここでは,句の区切りとして空白を挿入した。
古への 神代の奇しき 物語り 朝な夕なに 御魂砕きつ
心血も 涸れなんとする 骨も肉も 砕けなんとす 物語して
こまごまと 真理を説きし 神の書 拝読するたび 開く神国
物語 聞く度毎に 我が胸は 蓮の薫る 心地こそすれ
わが胸の 曇りを払ふ 物語読む 人こそは 神の御使
図4のOCR結果の初めの5行を次に示す。
い。
村装大石五大
無神伊 吾天主大陸 肝憶方の
ス始 始々都 界は界の界神 の萬の上六 の大抵の 話の今を神 伸江津
大方の世人はことごと怪ば
肝の心の眼くらみ たる人の読むべき書にはあらじ
これら5行に近い文を探したが,困難を極めた。ただ,第5行は,何故か,この画像の最終行の次の文とほぼ一致している。
村肝の 心の眼くらみたる 人の読むべき 書にはあらじ
図5のOCR結果の初めの5行を次に示すが,改行位置を変え,スペースも入れている。
古への 神代の奇しき物語り 朝な夕なに 御魂砕きっ
心血名 湖れなんと す。 肉 ち 砕け なんとす 物語 して
とまとまと 真理を説き し 神の雷 拝読するたび 開く 神 国
物語 開く度毎に 避の無 る 心地こそすれ
わが胸 の 張 り を払小 物 語読む 人 と そ は 神の御 使
以上で見ると,二階調化した場合,使えると考えられる。スキャンの原本を座右に置いて,読み解くという作業はより熟読を強いられるので,より集中力も生まれて,入力する作業にメリハリが生まれるように思われる。機械的に原本をただただ入力するよりは良いのではないか,と考えるが,どうだろうか。
Adobe Photoshopでの作業が入ってくるのは,多少鬱陶しいことではあろうが,これをしないとOCRの成果は全く得られないのだから,結局はかなりの時間短縮を手にすることができるだろう。
さて,このAdobe Photoshopの作業を回避する方法として考えられるのは,スキャンの解像度を300 x 300 dpiではなくて,600 x 600,さらには1200 x 1200は,どうだろうか。
以上,Sep. 19, 2022記。
3.2 より高解像度では
600 x 600 (dpi)でスキャンすると,3.9MBになる。1200 x 1200 (dpi)になるとかなりの時間を要する。まるで動いていないかのようで,12.3MBにもなる。Googl DriveのOCRは2MBまでだから,使えない。
400 x 400 (dpi)はどうだろう,1.9MB。300と所用時間に大きな差を感じない。プレビュー.appで回転すると2MBになる。図6には400 (dpi)と600 (dpi)のスキャン画像ファイルについて,そのファイルサイズを比較している。
図6には,議論を進める上で意味のあると思われるファイルにa_〜c_を頭に追加した。
a_Scan…400.jpgは,400 (dpi)でスキャンして,プレビューで回転した画像ファイル2MBである。
b_Scan…400_cutonly_black&white.jpgは,a_ファイルをAdobe Photoshopで必要部分を切り取って,2階調化したもの796kBである。
c_Scan…600_cut.jpgは,600 (dpi)でスキャンして,プレビューで回転して必要部分を切り取った画像ファイル758kBである。
図6の残りの5ファイルについては,この研究を進める上で棄却すべきものか,すでに論じた300 (dpi)のもので,とにかく,説明は省く。
図6が示しているのは,結局のところ,b_とc_について,Google DriveのOCR処理をする価値はあると思っている。
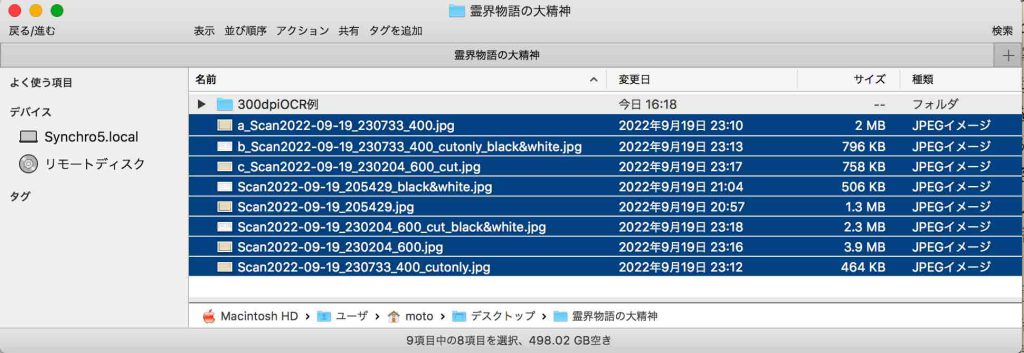
2階調化によって,何故か,ファイルサイズが増大し,600 (dpi)については,図6の下から3番目のファイルのように,2.3MBとなって,Google Driveが受け付けない。それで2階調化の前の段階でのファイルc_のOCRを実行すると結果は,300 (dpi)の図4と同様の結果になった。
で,400 (dpi)の2階調化したファイルb_のOCR結果と,300 (dpi)の二階調化したファイルのOCR結果(図5)の間を比較することになる。
下記は,400 (dpi) の2階調化したファイルのOCR結果の最初の部分であり,原本との関係を( )で示す。
————————————————
古への 神代の奇しを(を→き)物語り朝な夕なに御魂砕きっ (っ→つ)
心血を(を→も)洞(洞→涸)れなんとす骨 色(骨 色→骨も)肉 色(肉 色→肉も)砕けなんとす物語 して
こまごまと真 理を説き (空白→し)神の響(響→書)拝読する たび開 (空白→く)神国
(空白→物)語聞く度毎に我が胸は避(避→蓮)の 蘇(蘇→薫)る 心地と(と→こ)そすれ
(空白→わが胸の曇り)を払 小(小→ふ) 物 語読む 人 と(と→こ) そ は神の 御 使
村肝の心の壁(壁→塵)を払はんと暇ある毎に物語り(空白→読む)
(空白→古へのひじりも)未だ説 かさ(さ→ざ) り し鉢物船蔵(鉢物船蔵→弥勒胎蔵)の 吾は道 説 く
(空白→天火水) 地結ぶ紫色の宝玉は弥勒神示 (空白→の)物語なり」( 」→削除)————————————————
300 (dpi)と逐次比較することは,ここではしないが,400 (dpi)でスキャンすることでかなりOCR処理結果が向上している。
おわりに
以上から,今後は,400 (dpi)でスキャンして,Adobe Photoshopで切り抜きと2階調化を実施した方が良いという結果になった。
以上,Sep. 23, 2022記
